信息论 王立威
- 首先谈谈我对这门课的看法,王老师授课不会循规蹈矩地按照参考教材(黑皮书信息论),他是按照自己对信息论的理解和看法来的,所以前后知识的串联性会比较强一些,另外这门课是纯英文板书、中英夹杂授课。
- 整体上是按照信源编码和信道编码两方面展开,然后重点介绍了香农的一些工作,实际上信道方面在实际中会更重要、复杂一些,但是在各个领域包括计算中信源会涉及更多一些
L1
熵:随机信号的最低不可降低复杂度
- 量化信息的大小
- 如何用算法克服物理噪声
传输信息——需要事先约定 eg:传输一场比赛的结果 字符集{0,1}
| W | L | T(平局) |
|---|---|---|
| 0 | 1 | 10 |
| 0 | 11 | 10 |
第一种是否可行?
第二种是否可行? 可行->只传输一次
可行&效率max->平均编码长度?Minimize average code length
两个基本假设:
- infinite communication
- a prob distribution over the message
引入 pre-fix free 编码
- 无前缀->无歧义
- 无前缀<-×无歧义
Set : pre-fix free
Set : Uniquely decode codes 唯一可译码集合
,显然,但是实际上. ,使得平均码长达到最短,则,.注意前缀无码一定是唯一可译码,但反之则否
如何设计调整为?
Kraft Inequality
Assure is pre-fix free: Let be the length(numbers of bit) of ,则 不能都很短(为了prefix-free)
$$\sum_{i=1}^n 2^{-l_i}\le 1$$
若二叉树为满,则变为严格=
平均码长最短->二叉树为满树,则有
$$\sum_{i=1}^n 2^{-l_i}=1$$
如何求解?
Minimal Average Code Length
令message . Prob distribution . 目标是Find prefix-free with length ,同时有平均码长=(期望长度) 约束有:
求解:运用拉格朗日乘子法,
$$L=\sum_{i=1}^n p_i l_i + \lambda(\sum 2^{-l_i} - 1)$$
$$\frac{\partial L}{\partial l_i}=p_i-\lambda2^{-l_i}\ln2=0 \implies 2^{-l_i}=\frac{p_i}{\lambda \ln2}$$
$$\sum 2^{-l_i}=1,\ \sum p_i=1 \implies \lambda=\frac{1}{\ln2}$$
$$\therefore\ l_i=-\log_2 p_i \star$$
$$L^*=\sum_{i=1}^n p_i l_i=-\sum_{i=1}^n p_i \log_2 p_i$$
(是否为整数的差距不会超过1)两边同乘再求和可得,
定义:熵(entropy)
$$H(x)=\sum_{i=1}^np_ilog_2\frac{1}{p_i}=-\sum_{i=1}^np_ilog_2p_i$$
信息的信息量为
均匀分布的熵最大,单点分布的熵为0 e.g 对于伯努利分布,有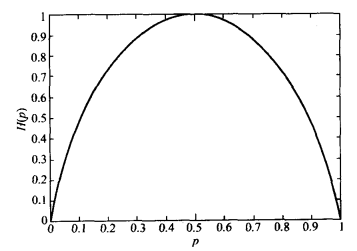
L2
Entropy被提出以qunantity information(量化信息)来描述uncertainty.
由琴生不等式可得.
信息量的刻画
- 随机变量:
- message :(可以看出概率小的事情信息量大)
Q:对于随机变量,其中可细化为
:为对局部信息的详细描述 :
什么样的码平均码长最短? Properties of optimal code
- 若则,
- 满足Kraft Ineq: for opt code
- 可以使成为兄弟结点
Huffman哈夫曼编码:一种简单的给出的最优五前缀编码的算法。
eg: 二源码 1:0.25 2:0.25 3:0.2 4:0.15 5:0.15
联合熵、条件熵、互信息(自信息)、KL散度(相对熵)
- 联合熵 Joint Entropy
两个有联合密度分布,如何定义一个联合熵?
$$H(X,Y)=-\sum_{x\in X}\sum_{y\in Y}P(x,y)log_2P(x,y)=-E[log_2P(x,y)]$$
显然 彼此独立时,;时, - 条件熵
定义:
$$H(Y|X=x_i)=\sum_{j=1}^nP(Y=y_i|X=x_i)log_2\frac{1}{P(Y=y_i|X=x_i)}$$
$$H(Y|X)=\sum_{i=1}^n\sum_{j=1}^nP(Y=y_i|X=x_i)log_2\frac{1}{P(Y=y_i|X=x_i)}$$
$$H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)$$
$$\Uparrow 推导:log_2P(X,Y)=log_2P(X)+log_2P(Y|X)两边取期望$$
$$H(X,Y)=-\sum_{x\in X}\sum_{y\in Y}p(x,y)log_2(p(x,y))$$
$$也即H(X,Y)=-\sum_{x\in X}\sum_{y\in Y}p(x)p(y|x)(log_2(p(x))+log_2(p(y|x)) )$$
L3
接续上一节的内容
$$H(X,Y)=H(X)+H(Y|X) (1)$$
$$H(X,Y)=H(Y)+H(X|Y) (2)$$
$$H(X,Y)\le H(X)+H(Y)(3)$$
Combine (1)&(3) and (2)&(3) 可得conditions reduce entropy
$$H(Y)\ge H(Y|X)$$
$$H(X)\ge H(X|Y)$$
则有:
$$H(X)+H(Y|X)+H(Y)+H(X|Y)=2H(X,Y)$$
$$H(X)+H(Y)-H(X,Y)=H(X,Y)-H(Y|X)-H(X|Y)$$
$$=H(X)-H(X|Y)=H(Y)-H(Y|X)$$
那么我们可以取量化这样一个量或: X与Y重叠那部分的信息量。
互信息(自信息):
$$I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)$$
$$=H(X)+H(Y)-H(X,Y)$$
$$=\sum_{x,y}p(x,y)log_2\frac{p(x,y)}{p(x\ne y)}$$
$$=I(Y;X)$$
接下来可以进一步探讨多元形式
$$H(X_1,X_2,…,X_n)=\sum p_{1,2,…,n}log_2\frac{1}{p_{1,2,…,n} }(Joint\quad Entropy)$$
同理的定义
我们有:
$$H(X_1,X_2,…,X_n)=H(X_1)+H(X_2|X_1)+…+H(X_n|X_1,…,X_{n-1})$$
这样在知道一串码和其概率分布时可求其熵,但这样我们的pmf时理想化的
True PMF is
我们的近似:
两种码长差多少?
相对熵/KL散度
$$D(P||Q)=\sum_{x\in X}p(x)log_2\frac{p(x)}{q(x)}=E_qlog_2\frac{p(x)}{q(x)}$$
Question:P、Q的KL距离和1维欧式距离之间关系?
$$D(P||Q) = \sum_{i} p_i \log \frac{p_i}{q_i}$$
$$\sum_{i=1}^n p_i \log \frac{p_i}{q_i} \ge \frac{1}{2} \left( \sum |p_i - q_i| \right)^2 \quad \text{(Pinsker)}$$
ps:大部分时候对数的底取决于编码空间,公式中可转换,大部分时候是以2为底,有些情况下是10或者e方便推导
简单推导:则模型可化为
特例:伯努利分布
$$KL(P||Q)=plog\frac{p}{q}+(1-p)log\frac{1-p}{1-q}$$
$$||P-Q||_1=|p-q|+|(1-p)-(1-q)|=2|p-q|$$
L4
- Entropy Rate 熵率
eg. 为
(1).
(2).最短平均码长=1 bit 为最优码长的下届,何时为下确界? 无限次传输时,最短码长还是0.07 bit吗? (受限于码长必须是整数) 平均每次的码长即为:
$$\frac{TH(X)+1}{T}=H(X)+\frac{1}{T}$$
当,.
真实信源信源是一个随机过程,
假设极限存在,定义平均每一时刻的信息量增长:
$$H(X)=lim_{T\to \infty}H(X_T|X_1,X_2,…,X_T)$$
即为熵率:序列长度的增长速率
- Differential Entropy (微分熵)
仿照离散型对连续型随机变量的讨论.
考虑,连续型随机变量的熵为
但是可以离散化
可以从形式上定义一个Entropy $$h(x)=-\int f(x)\log_2f(x)dx=-E\log f(x)$$
当退化为 时
$$H(X_{\Delta})\approx h(x)+\log_2\frac{1}{\Delta}$$
如何证明?
$$H(X_{\Delta})=-\sum p(x)\Delta\log_2p(x)\Delta dx$$
$$(p(x)\Delta\approx \int p(x)dx)$$
$$\approx -\int p(x)\log_2p(x)\Delta dx$$
$$=h(x)+\log_2\frac{1}{\Delta}$$
反直觉的一件事:differential entropy不过是形式化定义而已
由以上的推导,我们由以下几个结论:
- 考虑离散
$$H(X)=H(Y)=H(Z)$$ - 考虑连续
$$h(Y)=h(X)+\log_2a$$
如何证明连续的情况? $$\star\int P_Y(y)dy=\int \frac{1}{|a|}P_X(\frac{y}{a})dy$$
$$h(Y)=-\int P_Y(y)\log_2P_Y(y)dy$$
$$=-\int \frac{1}{|a|}P_X(\frac{y}{a})\log_2(\frac{1}{|a|}P_X(\frac{y}{a}))dy$$
$$=-\int P_x(X)\log_2(\frac{1}{|a|}P_X(x))dx$$
$$=h(x)+\log_2|a|$$PS:概统知识 已知的概率密度函数与的概率密度,如何得到式?
$$F_Y(y)=P(Y\le y)=P(aX\le y)$$
$$(1).a>0 \quad P(aX\le y)=P(X\le \frac{y}{a})=F_X(\frac{y}{a})$$
$$(2).a>0 \quad P(aX\le y)=P(X\ge \frac{y}{a})=1-F_X()\frac{y}{a}$$
$$1.a>0 \quad P_Y(y)=\frac{\mathrm{d} }{\mathrm{d}y }F_X(\frac{y}{a})=P_X(\frac{y}{a})\frac{1}{a}$$
$$2.a<0 \quad P_Y(y)=\frac{\mathrm{d} }{\mathrm{d}y }(1-F_X(\frac{y}{a}))=-P_X(\frac{y}{a})\frac{1}{a}=P_X(\frac{y}{a})\frac{1}{|a|}$$
$$\therefore P_Y(y)=\frac{1}{|a|}P_X(\frac{y}{a})$$
求
$$h(x)=-E\log_2p(x)=-\frac{1}{\ln2}E\ln p(x)$$
$$\ln p(x)=-\frac{1}{2}\ln (2\pi \sigma)-\frac{(x-\mu)^2}{2\sigma}$$
$$E[\ln p(x)]=-\frac{1}{2}\ln (2\pi \sigma)-\frac{1}{2\sigma}E[(x-\mu)^2]$$
$$=-\frac{1}{2}\ln (2\pi \sigma)-\frac{1}{2}$$
$$\therefore h(x)=\frac{1}{2}\log_2(2\pi e\sigma^2)$$
$$\Longrightarrow E[g(x)]=\int_{-\infty}^{+\infty}g(x)p(x)dx $$
L5
Differential Continuous entropy在上一节中已经进行了清晰的定义,沿用这些概念,定义一些新概念。
- Joint differential entropy 联合熵
$$h(X,Y)=-\int f(x,y)logf(x,y)dxdy$$
where is he joint pdf of X,Y - conditional differential entropy 条件熵
$$h(X|Y)=-\int f(x,y)logf(x|y)dxdy$$
$$=h(X,Y)-h(Y)$$ - Mutual Infoimation 互信息
离散情况:
若为连续随机变量则有定义:
$$\int f_{XY}(X,Y)log_2\frac{f_{XY}(x,y)}{f_X(x)f_Y(y)}dxdy$$ - KL dicergence 相对熵
定义为两个(连续随机变量)定义:
$$KL(f||g):=\int_{-\infty}^{+\infty}f(x)\log\frac{f(x)}{g(x)}$$
$$KL(P_{\Delta}||Q_{\Delta})=^{\Delta\to 0}=KL(f||g)$$
L6
Kolmagorov Complexity 柯尔莫哥洛夫复杂度
对于 determinist object有最优描述,例如圆(o,r) 矩形(o,a,b),why optimal is (o,r)? 对于random object如何?
另一个e.g.描述一段序列
- 对与0,0,…,0全为0 显然容易
- 011011… 显然也容易
- 110101001… 本身无规律 方法只有copy序列本身
引入一个问题:对于一个给定问题,讨论可用一段代码计算求解问题
- computer:能用代码实现
- 不computer:不能用代码实现 e.g. 表示所有实数 e.g. 多元方程整数解的存在
- Problems Decision Problems (eg 给定)
- Algorithms 一段代码(图灵机有限步内有解)
存在大量Problems(不可数多)没有Algorithms(可数多),事实上Problems是A lgorithms数量的幂级
[实变函数]一个集合和它的幂集无一一对应的关系
Halting Problem:给定代码能否在有限步停下来的问题
哥德尔不完备定理:若一个公理体系是内无矛盾的,则存在大量的statements无法被证明/证伪
Kolmogorov complexity
柯复杂度定义为:若字符串
$$K(x):=min|P|\quad P\to \text{代码}$$
$$u(P)=x:\text{执行代码输出为}x$$
对于某一个universal Turing Machine:
Q1. 对于不同的图灵机他们的有本质区别吗?
结论:为两个universal T.M,则存在使得对
Q2.固定?(怎么找到最短代码)
枚举?不可行,不存在一个算法可以决定program P 能否把输入x在有限步生成。
猜想&证明:Kolmogorov complexity不可计算?
Them is not computable
compute using : if output
proof:若存在算法 计算 for
这是的长度是固定的,
取,其中若
compute using : if output 只调用枚举,长度不大于
设$$K(S)\to \ge m+1$$
生成了一个复杂度大于其长度的代码,这与定义的“最小”矛盾Kolmogorov complexity ,即不应超过的长度
最大熵分布估计 从部分信息估计概率密度函数
常见:矩约束
$$\int f(x)dx=1$$
$$\int xf(x)dx=r_1$$
$$…$$
$$\int g_i(x)f(x)dx=r_i\text{(泛化形式)}$$
最大熵分布估计:从所有信息里面选Entropy最大的
$$max\quad -\int f(x)\ln f(x)dx \quad s.t.\quad \int f(x)dx=1,\quad \int xf(x)dx=r_1 …$$
例题:矩约束为
$$PS:D(x)=E[(x-E(x))^2]=E[x^2]-(E[x])^2=\int x^2f(x)dx$$
解:首先构造拉格朗日函数
$$ \mathcal{L} (x,f(x))=-f(x)\log f(x)+\lambda_1f(x)+\lambda_2xf(x)+\lambda_3x^2f(x)$$
$$ \mathcal{J} (f)=\int_{+\infty}^{-\infty}\mathcal{L}(x,f(x))dx-\lambda_1-\lambda_2*0-\lambda_3\sigma^2 \quad \text{(泛函)}$$
$$\frac{\mathrm{d} \mathcal{L} }{\mathrm{d} f(x)}=-\log f(x)+(-f(x))\frac{1}{f(x)}+\lambda_1+\lambda_2x+\lambda_3x^2 $$
$$\therefore f(x)=e^{\lambda-1+\lambda_2x+\lambda_3x^2}\quad \text{即为正态分布}$$
L7
Channel Coding 信道编码
- 信道噪声
- 算法减少(纠正)错误
重复编码 0—>000 1->n1 解码:最近邻
- …
Lower bound -
给定t,m估计n的下界Sphere packing bound
$$M\le \frac{2^n}{\sum_{i=0}^t\binom{n}{i} }$$
总空间至少容纳 个球给出的下界(至少多大才能支持个码字纠正位错误)
Upper bound 上界(存在性分析)
给定求最小的,使得必然存在:
- 单对坏概率上界 Chernoff界
$$i\ne j \quad P(d_H(C_i,C_j)<\delta n)<e^{-\theta(n)}$$ - 全局坏概率
$$P(\exists i\ne j,d_H(C_i,C_j)<\delta n)<C_{\alpha}^{2^m}e^{-\theta(n)}$$ - 概率小于1
$$C_{\alpha}^{2^m}e^{-\theta(n)}<1$$
GV 线性关系 使得
汉明码(至多纠正一个错误) 二元域的矩阵 零空间
L9
Message ->Error correcting Code.
- Sphere packing bound
- G. V. bound(Gilbert–Varshamov bound)
- Eifficient Encoding/Decoding Algorithm
Hamming Coding
列线性无关,任意两列之和不为第三列
解码 correct 1-bit error
编码目的
- 信息量: 码字
- 生成矩阵:生成矩阵 由 零空间的4个基向量 构成, ,因此
- 码字是基向量的线性组合
- 生成矩阵的标准形式
$$G=[I_4|G_3]$$
$$c=[a|G_3a]\to \text{[信息位|监督位]}$$ - 监督矩阵的置换
$$H=[P|I_3]\to G=(\frac{I_4}{P^T})$$ - 生成矩阵
[n,k,d]:
- n:码字长度
- k:信息位长度
- d:最小汉明
L10
[n,k,d]->[m+1,k+1,d+1] 其中d为odd,d+1为even
方法: 通过添加全局奇偶校验位(Overall Parity Check)实现,使最小汉明距离增加1.
循环编号 由上往下每一行向右偏移一位
- 噪声信道如何模拟?
- 给定噪声信道 ,X会接受多少信息?
$$I(X;Y)=D(P_{XY}||P_XP_Y)$$
信道容量:
对所有的输入,互信息最大值代表最大可靠传输速率
信道编码定理:
L11
渐进充分性(AEP)i.i.d
大数定理及其扩展 为概率分布
$$P(|\frac{1}{n}\sum X_i-E(x)|\ge\varepsilon)\to0(n\to\infty)$$
函数的定义下:
$$P(|\frac{1}{n}\sum g(X_i)-E(g(x))|\ge\varepsilon)\to0$$
熵的定义下:
$$P(|\frac{1}{n}\sum \log\frac{1}{p(x_i)}-E(\log\frac{1}{p(x)})|\ge\varepsilon)\to0$$
典型集
则有
$$\log P(·)=-nH(X)$$
$$\sum_{x\in A}p(x)\approx 1$$
$$|A|2^{-nH(x)}\approx1$$
$$|A|\approx2^{-nH(x)}$$
联合典型序列 定义联合AEP
$$i.i.d\quad (X_1,Y_1)(X_2,Y_2)…(X_n,Y_n)\sim P(X,Y)$$
联合分布概率
$$P_{XY}(·)\in 2^{-n(H(X,Y)\pm \varepsilon)}$$
边缘分布
$$P_X(·)\in 2^{-n(H(X)\pm \varepsilon)}$$
$$P_Y(·)\in 2^{-n(H(Y)\pm \varepsilon)}$$
[采样相关] 如何生成?
固定序列相应的采样典型序列 is
考虑独立的典型序列,则能构成典型序列的概率为:
$$\frac{2^{nH(X,Y)} }{2^{n(H(X)+H(Y))} }=2^{-nI(X;Y)}$$
L12
香农信道编码原理 Shannon Channel Coding Theorem
Proof Shannon Part1(Assume R<C)
- raw message 服从均匀分布
- Design codeBook
$$m_1\to C_1=(C_11,C_12,…,C_1n)$$
$$m_2\to C_2=(C_21,C_22,…,C_2n)$$
$$…$$
$$m_{2^{nR} }\to C_{2^{nR} }=(C_{2^{nR_1} },C_{2^{nR_2} },…,C_{2^{nR_n} })$$
idea random coding
$$P(X)=argmax_{\rho (x)}I(X;Y)$$ - Decoding algorithm/mode
Upon receiving
寻找唯一码字
即满足联合典型序列(AEP),需要考虑以下情况:
(a) 无码字与y联合 解码失败(如y本身非典型) 不考虑这种情况
(b) 多码字与y联合 解码失败
(c) 唯一码字与y联合 无需证明
对于情况(b):y为联合典型概率为
时,,
其本身有
$$P((b))\le 2^{nR}·2^{-nI(X;Y)}=2^{n(R-I(X;Y))}=2^{n(R-C)}$$
L13
范式不等式(Fan’s Inequality)
Theorem.
用Y估计X 作为X的估计
最小化错误率
$$P_e\ge \frac{H(X|Y)-1}{\log|\mathcal{H}|}$$
Proof Shannon Part2(Assume R>C)
消息均匀分布
信道输出,则互信息
证明
$$I(M;Y^n)=H(M)-H(M;Y^n)$$
$$H(M;Y^n)=H(M)-I(M;Y^n)$$
$$H(M)=nR\quad I(M;Y^n)\le nC$$
$$H(M;Y^m)\ge n(R-C)$$
设
$$P_e\ge \frac{n(R-C)-1}{nR}\approx \frac{R-C}{R}=\varepsilon_0 > 0 \quad (R>C) $$
费希尔信息(Fisher Information)与克拉美劳不等式(Cramer-Rao Inequality)
- 无偏估计
目的:用估计
$$\hat{\theta}=\phi(x_1,…x_n)\quad \phi:X\to R$$
无偏估计有下届 即为的无偏估计 - 费舍尔信息(Fisher Information)
定义分数函数
$$S(X;\theta):=\frac{\partial }{\partial \theta}\ln f(X;\theta) $$
$$E(S(X;\theta))=\int S(X;\theta)f(x;\theta)dx$$
$$=\int \frac{\partial }{\partial \theta}\ln f(x;\theta)·f(x;\theta)dx$$
$$=\int\frac{\partial }{\partial \theta} f(x;\theta)dx$$
$$=\frac{\partial }{\partial \theta}\int f(x;\theta )dx$$
$$=\frac{\partial }{\partial \theta}1=0$$
$$E(S^2(X;\theta))=Var(S(X;\theta))$$
定义费舍尔信息:
$$I(\theta)=Var(S(X;\theta))=E[S(X;\theta)^2]$$
$$Var=E[(X-E(X)^2)]=E(X^2)$$
等价于
$$I(\theta)=-E(\frac{\partial^2 }{\partial \theta^2}\ln f(X;\theta))$$ - 克拉美劳不等式
无偏估计
分数函数:
$$E(\nabla_\theta \ln f(X;\theta))$$
Fisher information:
$$-E(\nabla_\theta^2 \ln f(X;\theta))$$
Camer-Rao:(两者之差时半正定的)
$$Cov(\phi(X))\ge I(\theta)^{-1}$$
L14
通信复杂度(Communication Complexity)
定义:计算函数 所需交换的最大比特数
时序矩阵
分块数:将函数的真值表分解为若干时序矩阵的最小数量
通信复杂度的下界:
$$CC(f)\ge \log_2\mathcal{X}(f)$$
每个时序矩阵对应一种通信协议路径(固定的比特序列) 若时分块数,则至少需要来区分(因比特可表示种)
示例1:传达需要多少比特?
若包含对角线元素则不能包含非对角线元素,否则通信协议会混淆,则每个对角线必须单独构成一个矩阵,共个矩阵
至少需要n比特通讯示例2:传达需要多少比特?
$$\mathcal{X}(NAND)\ge 2^n \quad CC(F)>n$$
$$f(x,y)\quad M(f)_{2^n\times2^n}\to Matrix$$
$$M(f)\quad\text{into some rank 1 matrices}$$
$$rank(M(f))\le \mathcal{X}(f)$$
$$rank(A+B)\le rank(A)+rank(B)$$
L15
PNT素数定理
$$P\in[n^{100},n^{101}]\quad P\le m\sim\frac{m}{lnm}\quad \text{P存在性有保障}$$
Protoacl
$$Alice:x\in{0,1}^n \quad Bob:y\in{0,1}^n$$
- 随机选择一个素数
- Alice选择一个
- Alice将映射为多项式
- Alice send to Bob
- 接收compute 比较 若相等,则为1否则为0
若说明为的根
求是根的概率
$$h(x)=\sum_{i=0}^{n-1}(x_i-y_i)t_i\quad mod \quad p$$
其为非0多项式,且次数(有限域熵多项式根的定理),即最多 个根
$$P(error)\le \frac{n-1}{p} \quad p\ge n^{100}$$
$$\therefore \frac{n-1}{p}\le \frac{n}{n^{100} }\le o(n^{-99})$$
Max Entropy(多元情况)
最大熵分布是一个多元高斯
$$X\to d维 \quad E(X)=0\quad Cov(X)=XX^T=\Sigma$$
Let
$$D(X||Y)=\int f_X(t)\ln\frac{f_X(t)}{f_Y(t)}dt$$
$$=-h(x)-\int f_X(t)\ln f_Y(t)dt$$
$$=h(Y)-h(X)\ge0$$
由d维向量,可证:
$$f_Y(t)=\frac{1}{(2\pi)^{\frac{d}{2} }det(\Sigma)^{\frac{1}{2} } }exp(-\frac{1}{2}t^T\Sigma^{-1}t)$$
$$\ln f_Y(t)=-\frac{d}{2}\ln(2\pi)-\frac{1}{2}\ln det(\Sigma)-\frac{1}{2}t^T\Sigma t \quad (1)$$
$$-\int f_X(t)\ln f_Y(t)dt=\frac{d}{2}\ln(2\pi)+\frac{1}{2}\ln det(\Sigma)+\frac{1}{2}\int f_X(t)t^T\Sigma^{-1}tdt$$
$$t^T\Sigma^{-1}t\to E_X[t^T\Sigma^{-1}t]=tr(\Sigma^{-1}E[tt^T])$$
$$=tr(\Sigma^{-1}\Sigma)=tr(Id)=d$$
即
$$\frac{1}{2}\int f_X(t)t^T\Sigma^{-1}tdt=\frac{d}{2}\quad (2)$$
$$-\frac{d}{2}\ln(2\pi)+\frac{1}{2}\ln det(\Sigma)=\ln((2\pi)^{\frac{d}{2} }det(\Sigma)^{\frac{1}{2} })=\ln\frac{1}{f_Y^*(0)}$$
$$h(Y)=\frac{d}{2}\ln(2\pi)+\frac{1}{2}\ln det(\Sigma)+\frac{d}{2}$$
$$h(Y)=\frac{1}{2}\ln((2\pi e)^ddet(\Sigma)) \quad (3)$$
将(1)(2)(3)带入原式即可证明